分布式ID生成策略
UUID
优点:
- 简单,不会重复。
缺点:
- 不安全,可以推算出mac地址。
- 生成的ID即不单调递增,也不趋势递归,不连续,不利于db存储。
使用场景:
可以用于服务间之间调用的唯一ID。
数据库主键
优点:
- 简单,单调递增。
缺点:
- 性能低下
- 不适用于订单号生成,容易被人推算出业务每日订单量
使用场景:
自增id的性能要求不高的场景,项目从0到1野蛮生长的阶段。
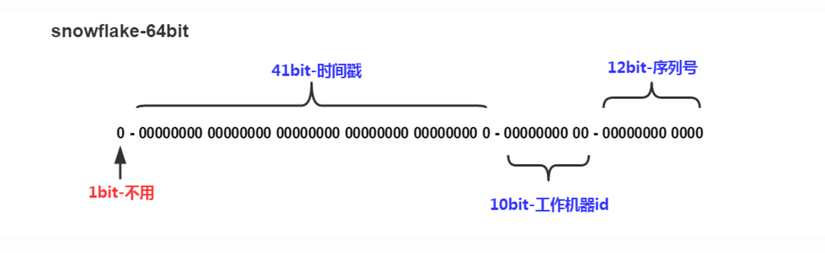
SnowFlake
优点:
- 生成简单,单机或分布式生成都可。
- 可以轻松定制化,加减id长度。
缺点:
- 生成的id会比较长(标准:1bit最高位,41bit存储时间戳+10bit存储机房和机器号+12bit有序自增序列),一毫秒能生成4096个id
- 需要解决时间回流问题。
使用场景:
对于生成订单号这些场景是非常适用的。
注:
1.关于算法中机器号的获取,可以通过zk的临时有序节点来得到。
2.时间回流问题,可以通过比对上次生成时间和当前时间,如果上一次的生成时间小于当前时间,则进行sleep等待处理。(一般时间回流会在5ms左右,闰秒)
Leaf-Segment(美团中间件)
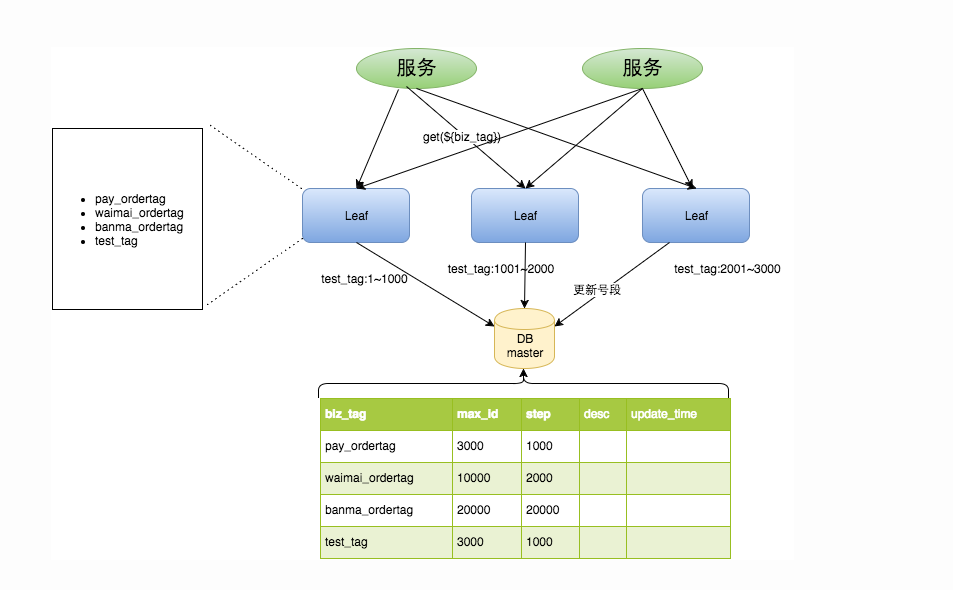
优点:
- 解决了数据组单机自增的性能瓶颈
缺点:
- 生成的ID并非单调递增,而是趋势递增,如生成的id可以会如下排列 [1, 7, 2, 3, 9, 5]
使用场景:
看业务对id是否单调递增敏感,用于生成用户id是不错的选择。
Leaf-Snowflake
同SnowFlake,中心化服务。